Le 03 juin 2021, au journal télévisé du soir, ça parlait tech/data.
Mais pas de manière très positive.
Un incident technique sur les réseaux de téléphonie d'Orange a affecté de manière partielle mais significative les numéros d'urgence du Samu, des pompiers ou de la police (le 15, le 17, le 18, le 112) sur l'ensemble du territoire national.
Le nouveau logiciel mis en place à la CAF pour calculer les aides au logement (APL) a entraîné des retards de paiement et des blocages de dossiers, aux conséquences lourdes pour les allocataires.
Il va falloir s'y habituer.
10 ans plus tôt, en Août 2011, Marc Andreessen écrivait dans un éditorial du Wall Street Journal que le logiciel mange le monde. Il désignait ainsi un tournant technologique et économique dans lequel les entreprises de tech/data sont en train de prendre le contrôle de larges pans de l'économie.
Avec une conséquence logique : les pannes des systèmes numériques ont des conséquences graves. Voire mortelle.
Et ça traduit une responsabilité supplémentaire pour ceux qui conçoivent ces systèmes.
3 sources de défaillances
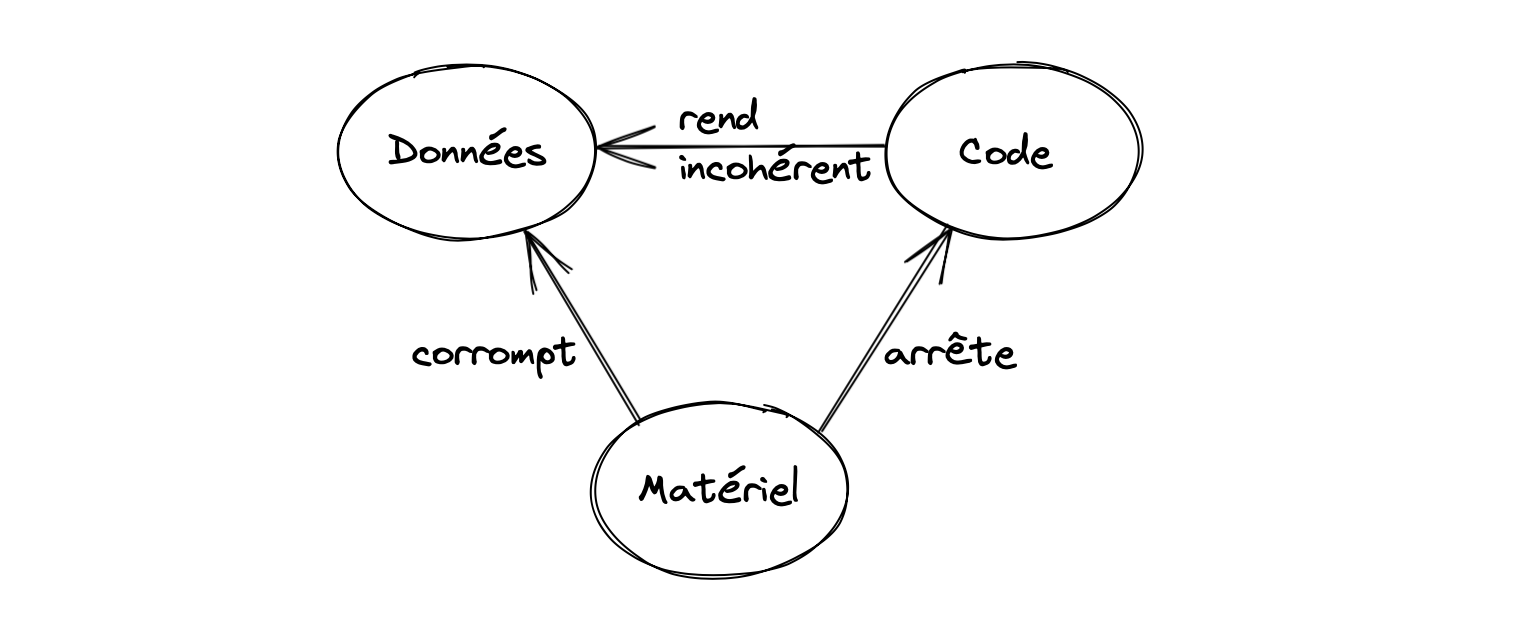
La panne d'un système peut avoir 3 causes :
- matérielle : le serveur brûle, ou il est débranché,
- logicielle : un bug (ou plutôt une erreur de conception) provoque une défaillance dans l'exécution du code. J'en ai déjà parlé ici.
- des données erronées sont utilisées en entrée, et ça donne n'importe quoi en sortie (garbage in, garbage out)
Avec bien entendu des cascades possibles, comme un bug qui provoque l'enregistrement de données incohérentes.
Continuer à fonctionner malgré tout
Vous connaissez sans doute l'origine militaire d'Internet. Son ancêtre "ARPANET" était un réseau de communication qui se voulait résistant à une attaque nucléaire.
Cette exigence a poussé la recherche de solutions techniques qui ont abouti au packet switching : les données à transmettre sont découpées en petits paquets qui vont être acheminés au travers du réseau sans prendre le même chemin.
Les paquets d'octets voyagent au travers des nœuds du réseau. Quand un nœud est en panne, le système fonctionne toujours car les paquets peuvent emprunter une autre route.
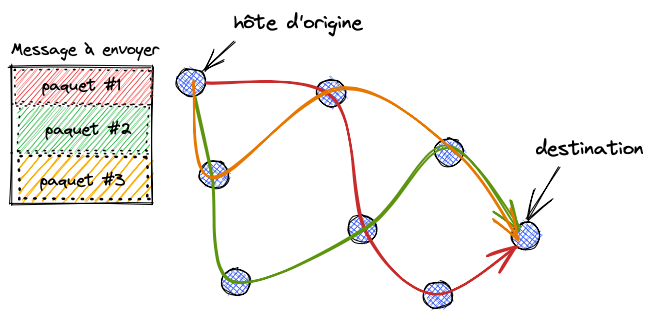
Alors tout arrive un peu dans le désordre, mais il y a une couche réseau (le "TCP" de TCP/IP) qui remet tout ça à l'endroit.
Et force est de constater que cette architecture a plutôt bien fonctionné jusqu'à présent.
Pourquoi ?
Parce qu'il n'y a pas de SPoF.
SPoF : Single Point Of Failure. Ou "Point de défaillance unique".
Il s'agit d'un élément dont la seule défaillance conduit à tout perdre.
Ce sont les maillons faibles de votre projet. Alors ça vaut la peine de consacrer un peu d'énergie pour les mettre sur la liste des trucs à corriger.
Pourtant je vois rarement des projets logiciels dans lesquels on se préoccupe explicitement de la tolérance aux pannes. La fiabilité est une sorte d'exigence implicite, sur laquelle tout le monde s'accorde mais personne ne travaille exclusivement.
Le Chaos Monkey
En 2011, Netflix déploie un nouvel outil de test nommé Chaos Monkey.
Sa particularité : il déroule ses tests sur l'environnement de production ! Il choisit un serveur de production au hasard, et le torpille.
L'objectif de Netflix est de contraindre la conception à s'accommoder des défaillances, plutôt que de serrer les fesses en priant pour qu'elles n'arrivent pas.
On simule un singe sauvage et armé qui déboule dans votre datacenter et qui casse des choses au hasard. Et tout doit continuer à fonctionner.
The name comes from the idea of unleashing a wild monkey with a weapon in your data center (or cloud region) to randomly shoot down instances and chew through cables — all the while we continue serving our customers without interruption
Mais comment Netflix parvient à faire ça ?
Simplement parce que son système est distribué sur de multiples instances hébergées dans le cloud d'Amazon Web Service. Il n'y a pas de point défaillance unique. Des instances peuvent tomber aléatoirement sans provoquer la panne totale.
C'est la vraie définition d'un cloud. Une architecture cloud ne consiste pas à seulement louer un serveur quelque part dans un datacenter dont on ne sait rien.
Un cloud est un ensemble de plusieurs constituants interconnectés et redondants, et qui est perçu de l'extérieur comme un seul truc.
Communication asynchrone et API stateless
Le cloud et sa tolérance aux pannes ont favorisé l'essor des technos qui :
- se distribuent nativement sur plusieurs noeuds (ex : ElasticSearch)
- font communiquer entre eux des composants distribués (Ex Kafka),
- orchestrent des composants, ou des containers répartis sur plusieurs nœuds (Ex : Kubernetes).
Sur la conception logicielle, ça change aussi un peu la façon de coder.
Pour faire communiquer 2 codes répartis sur 2 machines distantes, il faut composer avec la latence du réseau. Il faut attendre la réponse. Alors autant en profiter pour faire autre chose en attendant.
Voila une première tendance : les langages qui facilitent le codage des trucs qui doivent attendre d'autres trucs (Javascript, Elixir).
L'autre point concerne l'indépendance.
Puisqu'il s'agit d'être tolérant à la panne d'un composant, aucun d'entre eux ne doit détenir une information "exclusive", qu'il est le seul à posséder. Par exemple, si un serveur mémorise localement la session d'un utilisateur après une authentification réussie, ça ne marche pas. L'utilisateur sera déconnecté sauvagement en cas de panne du serveur et de basculement sur un autre.
Concevoir un système distribué impose donc plusieurs challenges techniques. Sur la façon de maintenir la cohérence des données copiées à plusieurs endroits. Ou sur la sécurité d'accès lorsqu'il existe plusieurs portes d'entrées.
Mais c'est le seul moyen de résister à un singe fou qui se met à tout casser.
Sources :
- Le packet switching : https://en.wikipedia.org/wiki/Packet_switching
- L'armée de singes de Netflix : https://netflixtechblog.com/the-netflix-simian-army-16e57fbab116