Les développeurs ont un rapport compliqué avec les bugs.
Connaissez-vous l'origine de ce terme "bug" ?
Il date précisément du 9 septembre 1947. A ce moment, Grace Hopper, une informaticienne talentueuse, travaille sur le calculateur Mark II de l’université Harvard aux Etats-Unis.
A cette époque, on parle plutôt de calculateur que d'ordinateur. Le micro-processeur n'existe pas encore, et la machine utilise des relais électro-magnétiques pour faire les calculs binaires.
Le premier bug
Ce jour-là, Grace Hopper constate que les résultats des calculs sont incohérents. Les résultats ne sont pas aléatoirement faux, ils sont constamment entachés de la même erreur.
En inspectant la machine, elle découvre un insecte (bug) coincé dans l'un des relais. Elle consigne dans son cahier de bord cette phrase devenue légendaire : "First actual case of bug being found". Et elle scotche l'insecte fautif.

Le terme est ainsi resté dans le vocabulaire de la tech pour désigner la cause d'un résultat faux ou d'un comportement anormal.
Avez-vous remarqué comme cette transposition est fallacieuse ?
En 1947, le bug était un élément étranger à la machine. Un insecte était à l'origine du problème, sans que Grace Hopper n'ait commis d'erreur de programmation.
Les bugs actuels n'ont rien à voir avec cette situation.
Les bugs actuels sont des erreurs de conception d'un logiciel.
Dont la pleine responsabilité repose sur le développeur. Et pas du tout sur l'intrusion d'un élément perturbateur externe.
Depuis, beaucoup d'énergie a été allouée pour trouver des méthodes de production d'un code sans bug. Ça devient crucial dans la mesure ou l'on trouve du code partout, en quantité et en complexité de plus en plus importante. Et que certains bugs peuvent tuer des gens.
On n'a toujours pas trouvé le moyen infaillible de faire du code sans bug. Mais des techniques ont émergé pour les réduire.
Tester
Le moyen le plus simple pour détecter (et éliminer) les bugs consiste à coder des tests automatiques.
Le code d'un test s'exprime ainsi :
considérant que <données d'entrée>, alors quand on fait <fonction à tester> on s'attend à avoir <données de sorties>.
Voir tous les tests réussis, ça inspire confiance sur l'absence de bugs, sans la garantir à 100%.
Une méthode encore meilleure consiste à coder les tests AVANT de coder les fonctionnalités. Avec cette démarche, on dispose d'une boussole qui guide le développement vers du code plus testable (donc plus modulaire) et optimisé (on a codé le juste nécessaire pour passer le test).
La principale limite des tests est que l'on s'intéresse surtout aux cas ou tout va bien. Puisqu'on doit définir le contexte des données d'entrées, on ne va pas tester tous les cas farfelus.
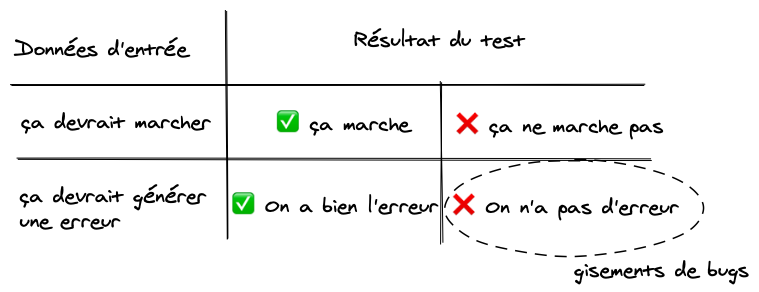
Pour combler ce manque, il existe des méthodes de "fuzzy testing" consistant à bombarder son code avec un grand nombre de données d'entrées aléatoires. Ça augmente facilement la surface de test, mais c'est en pratique assez peu utilisé hors des tests de sécurité ou end-to-end.
L'analyse statique
Une autre méthode consiste à soumettre le code que l'on écrit à un autre outil : l'analyseur statique.
Ce dernier va lire notre code (sans l'exécuter), et nous dire ou sont les bugs.
Hum, là je vais un peu vite. On est encore loin d'obtenir un tel résultat.
En pratique, les outils actuels se limitent à vérifier le respect de règles dans le code pour avertir le développeur d'une cause possible de bug. Le typage fort appartient à cette catégorie, puisqu'il permet au développeur d'expliciter lui-même dans son code des règles vérifiables avant d'exécuter le code.
J'ai eu l'occasion de travailler sur des outils d'analyse statique plus puissants, qui implémentent des techniques d'interprétation abstraite. Ils sont issus des travaux du couple de chercheurs français Patrick et Radhia Couzot. Ces outils ont servis à vérifier le code dans des systèmes embarqués, comme le logiciels de vol de l’Airbus 380. Mais ils sont encore peu répandus hors de ce domaine.
L'immutabilité
L'immutabilité consiste à prendre le problème à la racine, comme une mauvaise herbe.
Ça part du constat suivant : les bugs proviennent souvent des données qui ont été modifiées, et qui ont conduit le logiciel dans un état incohérent. Autrement dit, ce sont les modifications successives des données initiales (cohérentes au départ) qui provoquent leur corruption.
Alors prenons une solution radicale : interdisons la modification d'une donnée.
Alors là on se dit qu'on va avoir du mal à faire autre chose que des logiciels inutiles si on ne peut pas modifier l'adresse d'un client, ni même modifier la liste de ses clients.
Et pourtant si.
C'est même un concept essentiel de la programmation fonctionnelle.
C'est simple : on code des fonctions qui créent de nouvelles données de sortie à partir de données d'entrée sans jamais les modifier. Il n'y a plus "d'état" modifiable, seulement des fonctions qui génèrent un nouvel état à partir d'un ancien.
Alors oui, il faut faire un peu de gymnastique mentale pour s'accommoder de la disparition des variables modifiables.
Mais observez ce code Elixir de toute beauté pour créer une base de données clé/valeur SANS aucune variable pour la mémoriser :
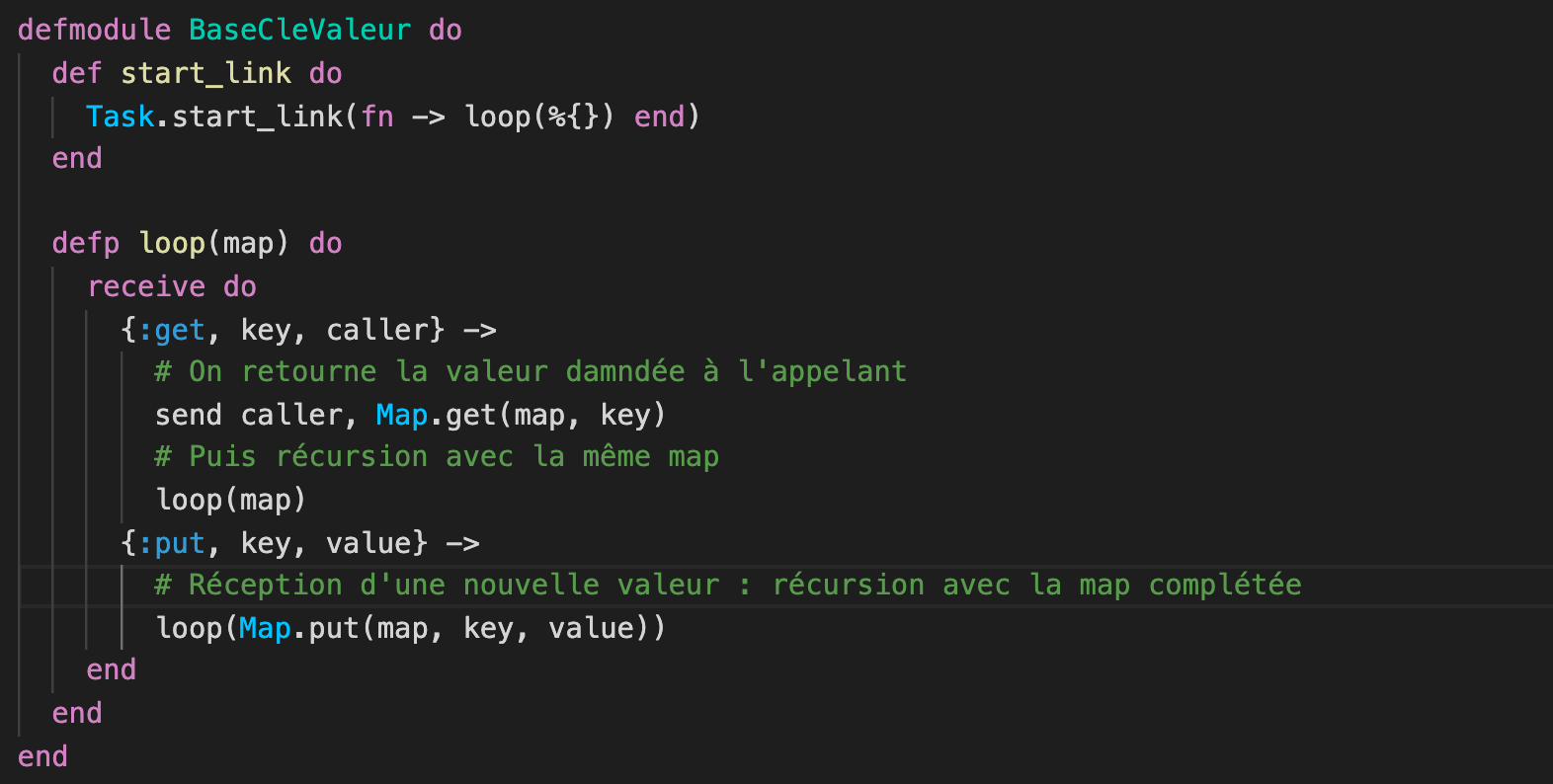
Toute l'astuce repose sur cette fonction récursive loop qui prend en paramètre une map (c'est une structure de données permettant de représenter des couples clé/valeur).
Cette fonction attend de recevoir une demande de la part d'un autre module. Cette demande peut être :
get: la lecture d'une valeur à partir de sa cléput: l'ajout d'une d'une nouvelle valeur, en passant en paramètre lakeyet lavalue
Dans les 2 cas, la fonction s'appelle elle-même, en passant en paramètre la map inchangée loop(map) ou une nouvelle map loop(Map.put(map, key, value).
Aucune trace d'une variable dans le module dédiée au stockage de la map.
Let it crash
Puisqu'on parle d'Elixir, ce langage propose aussi une approche fataliste mais pragmatique.
L'hypothèse est qu'on ne pourra jamais garantir l'éradication de toutes les erreurs de conception dans un logiciel complexe.
Alors c'est inutile de blinder son code avec les défenses nécessaires à gérer toutes les erreurs possibles, mieux vaut le laisser se planter, et le relancer immédiatement avec un nouvel état cohérent.
Cette façon de faire impose une architecture de modules qui vivent leur vie, sous l'oeil d'un superviseur bienveillant qui relancera ceux qui ont crashé.
L'intérêt est que l'on code le déroulement qui se "passe bien". Et uniquement lui. Si ça se passe mal, on le laisse planter et redémarrer, en s'arrangeant que ce soit un module suffisamment petit et indépendant pour que ça ne provoque pas une cascade de défaillance.
Un logiciel complexe sans bug, une utopie ?
Le graal du logiciel dont on sait démontrer l'absence d'erreur de conception n'est pas encore atteint.
On constate toutefois l'émergence de standards dans le développement logiciel qui contribuent à la fiabilité :
- le typage fort : annoter le code pour vérifier des règles avant l'exécution,
- les tests : pour vérifier la bonne exécution dans certains contextes,
- l'immutabilité : pour réduire le risque d'atteindre un état incohérent,
- la résilience : la capacité à s'arrêter et redémarrer sans conséquence notable.
Ces techniques sont intéressantes à conditions de ne pas affecter la lisibilité et la simplicité.
Il y a des codes dans lesquels on lit comme dans une fable de la Fontaine. On comprend tout de suite l'histoire qu'ils racontent.
Et on voit immédiatement les trucs qui clochent. C'est rarement des insectes.