
A la lecture de ce texte :
Hier soir, le quinze de France a battu les Anglais à domicile par 42 points d'écarts, du jamais vu depuis le début du tournoi des 6 nations.
De quoi ça parle ?
De sport, de rugby. On devine même que c'est une actualité récente ("Hier soir"), que c'est un match qui a eu lieu en Angleterre ("à domicile"), dans le cadre d'un tournoi international ("6 nations").
Du point de vue d'un amateur de sport français, c'est plutôt une bonne nouvelle, un sentiment positif.
On imagine d'ailleurs que la phrase a été écrite par un français : un journaliste anglais aurait peut-être parlé avec moins d'enthousiasme de déroute de l'équipe nationale, et aurait placé l'équipe Anglaise comme sujet de la phrase.
C'est une phrase riche, dont un humain peut extraire de nombreuses informations.
Et une machine ?
Qu'est-ce qu'elle peut "comprendre" de cette phrase ? Saurait-elle en retirer autant d'informations ?
Si oui, pourrait-elle le faire sur des milliers de phrases issues des journaux, des réseaux sociaux pour identifier les principales idées, ou les sujets émergents ?
Au travers de cette question, on aborde l'un des cas d'usage de l'iA : extraire de l'information pertinente à partir d'un gros volume de données désorganisées.
Qu'est-ce qu'un modèle de langage ?
L'un des domaines pour lesquels les progrès de l'iA sont spectaculaires est celui du traitement du langage naturel (NLP : Natural Language Processing). On dispose désormais de nombreux modèles de langage (la plupart open-source) pour analyser des textes.
Un modèle de langage est le résultat d'un calcul itératif (l'apprentissage). Les résultats de ce calcul sont des paramètres (plusieurs millions) qui vont servir à transformer des mots et des phrases en des représentations numériques.
Sa mise au point est coûteuse en temps de calcul et en ressources. Mais une fois publié, il offre un formidable point de départ pour réaliser des modèles dédiés à des tâches spécifiques : classification, réponses automatiques, reconnaissance d'entités, ...
Pour extraire de l'information d'une phrase, on part d'un modèle de langage que l'on va "affiner" pour réaliser cette tâche.
On va présenter 3 approches pour un cas d'usage classique : classer en 2 catégories (avis positif / avis négatif) les commentaires de clients qui ont acheté un livre de cuisine.
Méthode #1 : la classification supervisée
Pour catégoriser une phrase, l'approche la plus "simple" est l'apprentissage supervisé.
On constitue un jeu de données d'entraînement, constitué de phrases annotées (par des vrais gens) :
| Avis | Classement |
|---|---|
| enfin un livre clair et franchement les recettes ne sont pas compliquées à faire | Positif |
| Top. Le plein de bonnes idées. Je n'ai pas encore eu l'occasion de faire toutes les recettes de ce livres mais celles que j'ai fait étaient très bien | Positif |
| Déçu par ce livre de recettes. Certes facile mais qui ne donne pas du tout envie pour ma part. | Négatif |
Il faut plusieurs milliers d'exemples comme ceux-ci pour entraîner un modèle de classification. L'entraînement est dit supervisé car on dispose des "bonnes réponses" dans les données d'entrées. Le modèle apprend à les prédire sur des phrases qu'il n'a jamais vu.
Le principal inconvénient saute aux yeux : il faut construire le jeu de données. Mais il y en a un autre qui en découle : il faut connaître à l'avance les catégories. Dans l'exemple ci-dessus, on a défini un classement positif/négatif.
Mais si l'on souhaite ajouter une nouvelle catégorie "neutre" ?
Et bien il faudra dans ce cas revoir les milliers d'exemples et en ajouter d'autres pour tagger les avis "neutres". Puis ré-entraîner le modèle.
Méthode #2 : la vectorisation des labels
Il y a une astuce pour faire de la classification en NLP.
Les labels "positif", "négatif", "neutre" sont des mots en français. Ils peuvent donc être eux-aussi soumis à un modèle de langage qui va les transformer en un vecteur (pour en savoir plus : Transformer les mots en chiffres).
Ensuite, on peut comparer ce vecteur à ceux contenus dans la phrase que l'on cherche à classer. C'est possible puisqu'on a mis les mots de la phrase et le label dans le même espace vectoriel.
L'avantage de cette méthode est qu'elle n'impose plus de constituer un jeu de données d'entraînement. On utilise le modèle de langage "brut".
Le bénéfice collatéral est que l'on n'a pas à déterminer à l'avance les catégories ("positif", "neutre", "négatif").
Alors OK, il y a un inconvénient : ça ne fonctionne pas très bien !
Parce qu'on compare des vecteurs résumant un mot seul, sans aucun contexte.
Les résultats pourront être satisfaisants pour des phrases comportant des adjectifs connotés positivement ("merveilleux", "formidable"), mais pas pour les autres.
Par exemple, la phrase "enfin un livre clair et franchement les recettes ne sont pas compliquées à faire" comporte le mot "compliqué" qui, analysé isolément de son contexte, peut conduire à classer l'avis comme négatif.
Pour sortir de l'impasse, il faut analyser l'ensemble de la phrase. Passer de la vectorisation des mot à celle des phrases. Mais on se garde ça pour un prochain article.
Méthode #3 : l'inférence
En Septembre 2018, Facebook a publié un énorme jeu de données comportant 15 langues et 112,500 lignes.
En voici un extrait :
| Phrase de départ |
|---|
| Cela peut être notre tour de contrôle, suggère-t-il à Vance, en montrant du doigt un coin près d'une étagère. |
| Hypothèses | Classement |
|---|---|
| Les enfants jouent avec des avions jouets | Neutre (possible) |
| Quelqu'un ignore Vance | Contradiction (sûr que non) |
| Quelqu'un est en train de parler à Vance | Déduction (sûr que oui) |
Chaque ligne du jeu de données comporteune phrase de départ, une phrase d'hypothèse, et un classement du lien qui lie ces deux phrases selon 3 catégories :
- contradiction entre les 2 phrases,
- neutre,
- déduction.
A l'aide de ces de données, on va affiner le modèle de langage pour lui apprendre à prédire la "cohérence" de deux phrases.
Et là, on dispose d'un chouette outil, qui peut avoir pleins d'usages différents ?
On peut notamment lui soumettre ce couple de phrases :
- l'avis d'un client (que l'on cherche à catégoriser)
- et la phrase : "Cet avis est positif".
Si le modèle prédit un score élevé de cohérence, il se pourrait bien que l'avis soit effectivement positif.
Et en effet, ça fonctionne plutôt bien :
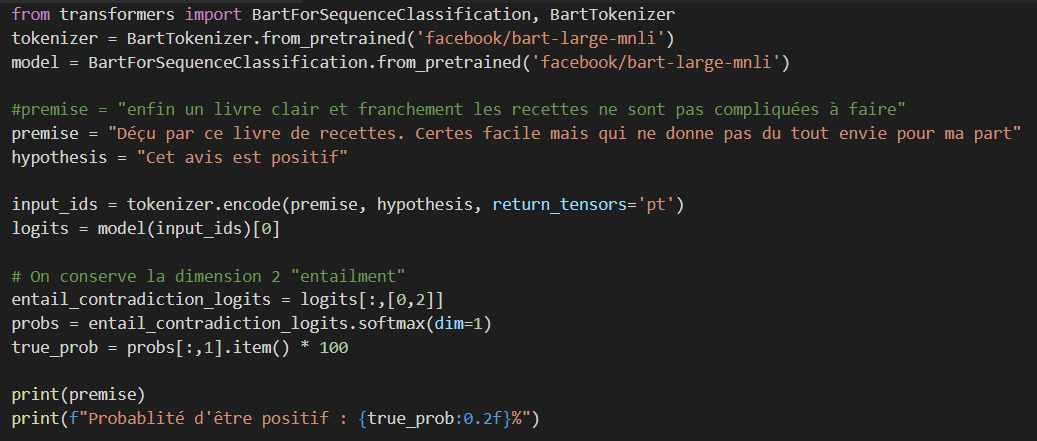
enfin un livre clair et franchement les recettes ne sont pas compliquées à faire
Probabilité d'être positif : 72.14%
Déçu par ce livre de recettes. Certes facile mais qui ne donne pas du tout envie pour ma part
Probabilité d'être positif : 3.06%
Pas mal !
Mais on peut aller plus loin, et réaliser la classification sur des labels variés.
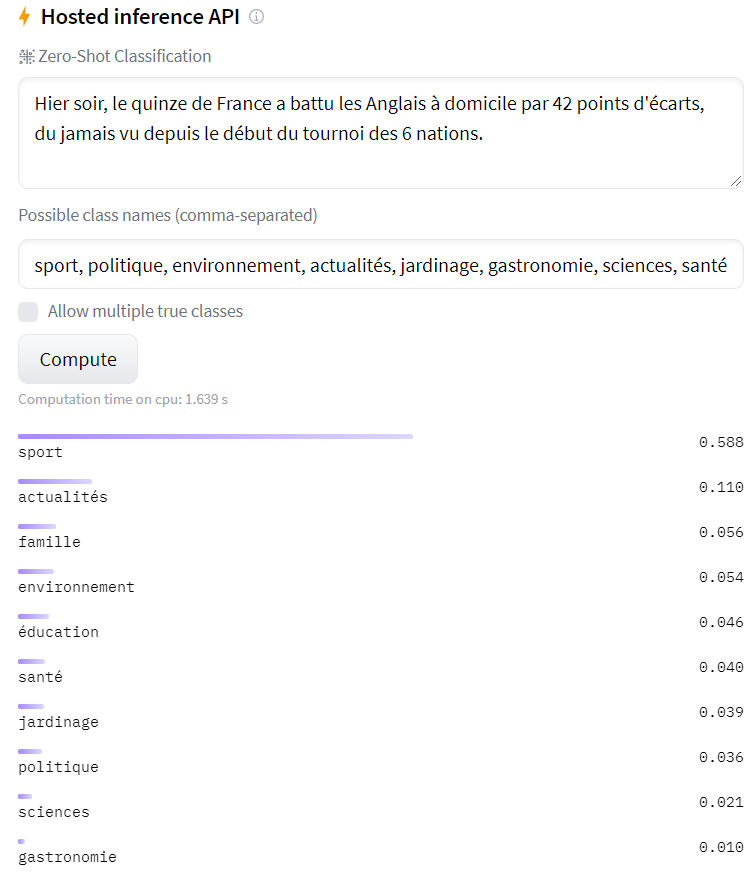
Reprenons notre exemple du début, avec la victoire de l'équipe de France, et évaluons le score face à une liste de thèmes : sport, politique, environnement, ...
Et bien là encore, le classement est plutôt pertinent (sport, actualités en tête) sans avoir réalisé d'entraînement sur ces labels :
Ça donne envie de tester soi-même, non ?
Et bien c'est possible sur le site de Hugging Face :

Vers des modèles "couteaux-suisse"
De puissants modèles entraînés sur des tâches assez génériques sont publiés chaque jour, notamment dans les domaines du langage naturel et de l'analyse d'images.
Ils offrent pleins d'opportunités pour tester de nouveaux usages, sans nécessiter de gros moyens techniques.
Juste de la curiosité pour comprendre la façon dont ils ont été construits, de l'imagination, des données à analyser et une méthode d'évaluation des résultats.
A vous de jouer !


