Il n'y a jamais eu autant à lire sur Internet que maintenant.
Une estimation approximative laisse penser qu’il existe 500 millions de blogs. Chaque jour, c'est environ 2 millions de nouveaux articles publiés.
La quantité a probablement davantage augmenté que la qualité. On lit quand même pas mal de contenu écrit pour Google, dont le seul objectif est de saturer la page avec les bons mot-clés pour figurer en première page des recherches.
Il n'empêche que l'on peut passer des journées entières à lire des pages dignes d'intérêts. Jusqu'à l'indigestion parfois.
Parmi les applications concrètes de l'intelligence artificielle, le traitement du langage naturel a probablement un rôle à jouer pour faire le tri, pour résumer, pour sélectionner.
Comment ?
En transformant les mots en chiffres, afin de pouvoir leur appliquer des calculs.
Je vous propose quelques explications sur la façon de faire cette transformation, en l’illustrant d’une application concrète.
Même si je pose ici et là quelques extraits de code, je ne vais pas détailler les algorithmes ni les bibliothèques. Retenons juste que :
les modèles de NLP les plus performants utilisent des transformers (non rien à voir avec les robots). Cette méthode d'analyse du langage naturel possède 2 avantages principaux :
- La performance : on prend en entrée des blocs de phrases complètes au lieu de faire du mot à mot. Ca consomme 10 à 100 fois moins de temps pour être entrainé sur un gros volumes de texte,
- Le couteau-suisse : le même modèle peut servir à plusieurs usages, sans besoin d'être entrainé spécifiquement.
- l'un des modèles de référence pour le NLP est le BERT (Bidirectional Encoder Representations from Transformers), mis au point par Google.
Ce qui est nouveau, c'est que cette technologie est devenue très accessible.
La preuve.
Je vais utiliser le modèle Camembert dont j'ai déjà eu l'occasion de parler.

Tokenisation : la transformation des mots en mot-clé
Dans un texte, il y a pleins de mots. Trop en fait.
Alors dans un premier temps, on va transformer les mots en des mot-clés que l'on nomme "token". L'objectif est de se constituer un dictionnaire limité de tokens, pour réduire le nombres de mots à gérer.
Par exemple, la phrase “Voici un exemple excessivement simple” devient :
<s> ▁Voici ▁un ▁exemple ▁excessive ment ▁simple </s>Des tokens marquent le début <s> et la fin de phrase </s>. L'adverbe “excessivement” a été découpé en 2 tokens : “excessive” et “ment”.
Chaque token a été associé à un numéro. Le vocabulaire du modèle Camembert comporte 32,000 tokens (ça aurait été beaucoup plus sans tokenisation).

Dans le dictionnaire des tokens, on a attribué au mot “Voici” le numéro 1119. “Exemple” le numéro 411.
Voilà une première étape pour convertir un mot en nombre.
Mais le meilleur est à venir.
Vectorisation
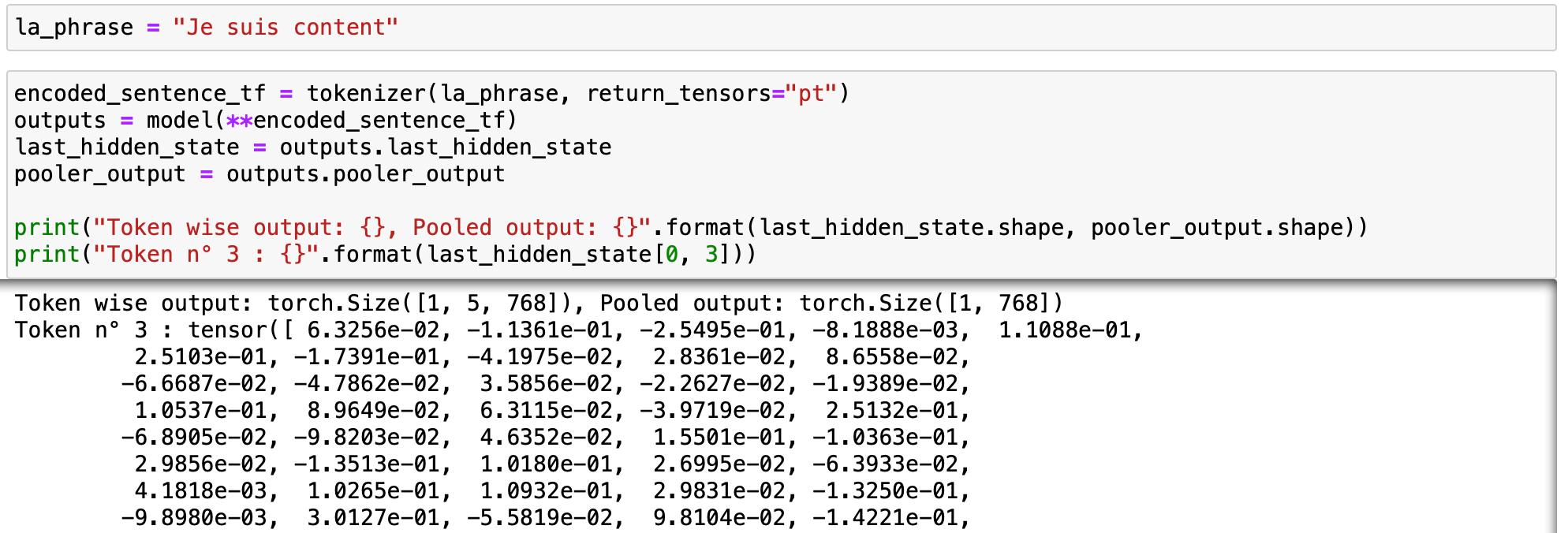
L'étape suivante consiste à transformer chaque token d'une phrase en un vecteur, c'est à dire une liste ordonnée de nombres.
Par exemple, dans la phrase “Je suis content”, le modèle attribue au mot “content” un vecteur comportant 768 valeurs : 6.3256e-02, -1.1361e-01, -2.5495e-01, -8.1888e-03, 1.1088e-01, ... (je vous épargne la liste des 763 autres valeurs !)
A quoi sert ce vecteur ?
Et bien il contient toute l'information sur la signification du mot, dans le contexte de la phrase. C'est là que la magie opère !
De quelle orange parle-t-on ?
Explorons un peu ça en comparant la similarité des vecteurs des mots de 2 phrases différentes. La similarité est comprise entre 0 et 100% (100% si les 2 vecteurs sont exactement identiques).
- Première phrase : "La pomme est orange".
- Deuxième phrase : "La pomme est verte".
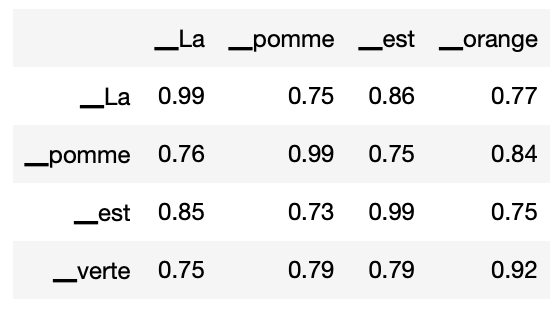
Le mot “pomme” de la première phrase est perçu comme similaire à 99% au mot “pomme” de la seconde phrase. En revanche, il est perçu comme similaire à 73% au verbe “est” de la seconde phrase.
Merci, il y avait bien besoin d'un modèle d'IA pour trouver ça…
Attendez avant de supprimer le mail. Observez la similarité entre “orange” et “verte”(à l’intersection de la ligne “_verte” et de la colonne “_orange”).
Elle est plutôt élevée, à 92%. C'est même la valeur la plus forte des mots qui ne sont pas identiques.
Voila un premier résultat intéressant : le modèle a détecté que le mot “verte” de la seconde phrase avait un peu le même sens que le mot “orange” de la première ?
Essayons de le tromper en comparant 2 autres phrases :
- Première phrase : "La pomme est orange".
- Deuxième phrase : "orange vend des téléphones".
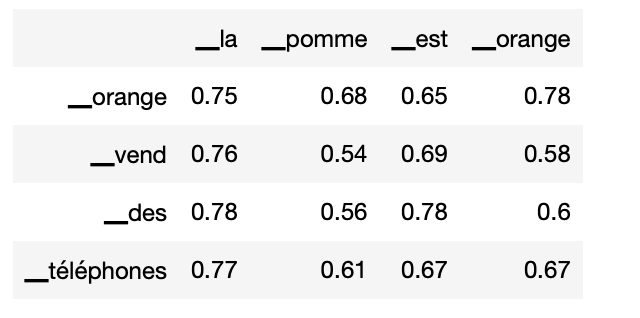
Le même mot “orange” est présent dans les 2 phrases, mais il n'a rien à voir (une marque commerciale, une couleur).
La valeur de similarité du mot "orange" dans ces 2 phrases est de 78%. D'ailleurs, globalement, les scores sont plus bas que ceux du premier couple, indiquant que les 2 phrases n'ont pas grand chose en commun.
Ainsi, le modèle détecte que le lien entre “orange” et “verte” (92%) dans le premier exemple plus fort que entre "orange" et "orange" (78%) dans le second même s'il s'agit du même mot.
Et ensuite ?
Toutes les techniques de traitement du langage naturel reposent sur la conversion des mots des humains en valeurs numériques exploitables par les machines.
Les progrès significatifs réalisés ces 3 dernières années ont permis de générer des valeurs numériques qui décrivent la signification et le contexte dans lequel le mot est utilisé. Ainsi, on va pouvoir entraîner des modèles pour analyser de gros volumes de textes afin d'en extraire des informations utiles :
- le texte parle-t-il d'un sujet d'une façon positive ou négative ?
- quels sont les principaux thèmes abordés ? Comment sont-ils liés entre eux ?
- contient-ils des réponses aux questions posées ?
- Quel résumé peut-on faire du texte ? Quel titre pourrait-on lui attribuer ?
Ces cas d'usage sont évidemment précieux pour le développement des moteurs de recherche. Mais les application possibles vont bien au-delà.
Les modèles pré-entrainés rendent ces techniques plus accessibles. On peut désormais explorer ces cas d'usage sans mobiliser d'énormes puissances de calcul.
Alors, ça vous dit d'essayer ?