Vous mettez combien de temps à trouver un mot dans le dictionnaire ?
J'ai l'impression que c'est interminable.
Tout semble bien rangé par ordre alphabétique. Ca devrait être facile.
Pourtant, on passe son temps à tourner les pages, puis à en sauter d'impatience pour revenir en arrière parce qu'on est allé trop loin.
Et encore, dans un dictionnaire, il n'y a pas beaucoup de données. Seulement 60,000 mot dans un petit Robert, et 300,000 dans le gros.
Alors on pense qu'un ordinateur va aller plus vite que nous pour trouver. Et bien non, lui aussi va errer dans la dichotomie des "c'était avant", et des "c'est après".
Pourquoi ?
Parce que c'est mal rangé pour trouver un mot.
Range tes mots !
Comment faire mieux ?
Imaginons que l'on dispose d'un index, qui nous donne le numéro de page du dictionnaire pour chaque mot.
Et cet index, on le construit ainsi :
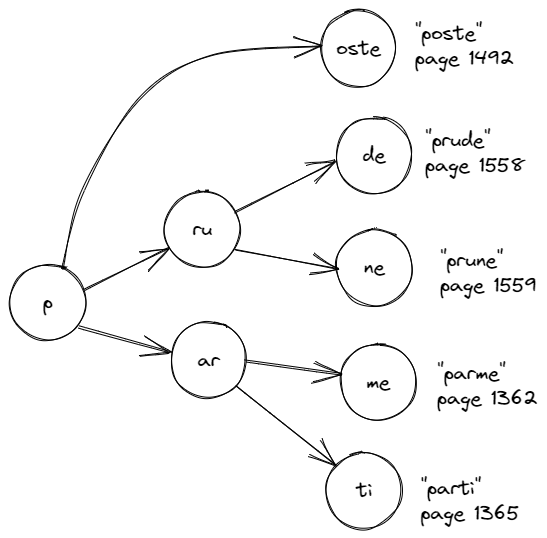
Alors OK, ce n'est pas évident à lire.
J'ai restreint l'index à un dictionnaire de 5 mots pour qu'il reste lisible : "poste", "prude", "prune", "parme" et "parti".
Voici le principe :
- vous épelez le mot recherché
- vous suivez le lien qui vous mène à la prochaine lettre
Exemple : cherchez le mot "prune". Si, si, allez-y.
En un coup d'oeil, vous avez trouvé le bon chemin.

Et s'il n'y a pas de chemin ? Alors c'est que le mot recherché ne figure pas dans le dictionnaire.
Encore mieux : à chaque lettre je peux suggérer à l'utilisateur un choix pour la prochaine. Comme lorsque vous entrez une adresse dans le GPS de votre voiture, lettre par lettre.
Avec un tel index, c'est devenu très rapide pour trouver un mot dans le dictionnaire.
La performance, c'est d'abord une histoire de rangement
Cette façon d'organiser les lettres sous la forme d'un arbre de recherche, c'est très malin.
Mais, il y a un revers à cette médaille : il va falloir construire l'index.
Ca va prendre des heures de calculs pour analyser mon dictionnaire et créer cet index.
C'est vrai.
Mais ce temps de calcul est une sorte de "préparation" des données. Il ne se trouve pas entre la demande de l'utilisateur et sa réponse. On a pré-mâché astucieusement les données dans le seul objectif de réduire le temps pour trouver un mot.
L'utilisateur se fiche des efforts qui ont été préalablement consacrés à construire l'index. Pour lui, seul le résultat de sa recherche compte.
Mais on a un deuxième problème : la duplication de données.
Au lieu d'un seul dictionnaire, on doit stocker en plus cet index (lui aussi très volumineux).
Les 2 documents sont liés : à chaque mise à jour du dictionnaire, il va falloir recalculer au moins une partie de l'index.
Honnêtement, on s'en fiche un peu car le stockage n'est plus un problème. Il est très peu couteux.
Par contre, l'accès au disque sera toujours moins rapide que de conserver les données en mémoire.
La réflexion sur l'organisation des données doit être poursuivie sur le champ de la compression : comment compresser la taille de l'index, sans affecter son potentiel, afin de rendre sa taille suffisamment faible pour permettre de rester en mémoire ?
Organiser ses données en fonction des usages
J'observe beaucoup d'entreprise qui veulent construire un entrepôt de données.
Elles veulent devenir data-centric. Pour mettre la donnée au coeur de leurs décisions.
Alors on importe goulûment des données qui viennent de pleins de sources différentes, pour les regrouper et les mettre en qualité (ex : supprimer les doublons).
C'est une bonne idée.
Sauf qu'on a seulement construit une énorme bibliothèque : elle contient plein de trucs rangés de façon à arranger le bibliothécaire qui doit remettre les livres en places.
Mais pas rangés pour optimiser le temps du lecteur qui cherche un bout de texte qui parle de quelque chose.
Un projet data, ce n'est pas qu'une affaire de collecte de données pour construire une bibliothèque géante. Il faut réfléchir aux usages : que va-t-on vouloir faire à l'aide de ces données ?
Et souvent, il y a matière à innover dans la façon d'organiser les données selon ces usages:
- soyez malin sur les algorithmes et les structures pour créer des index sur-mesure,
- Optimisez le volume des index pour permettre de les placer en mémoire, en compressant si besoin,
- déployez des pipelines de transformation, qui vont se charger de construire au fil de l'eau les index.
Ainsi, vous obtiendrez un moteur de recherche qui répond rapidement. Ou un dashboard dont les valeurs se mettent à jour à la vitesse de la lumière.
Pour ranger vos données, pensez au lecteur.
Pas au bibliothécaire.